Problem 1.1 Linear Transformation of a Random Variable
LOTUS
LOTUS (Law of the Unconscious Statistician) Theorem:
It’s all about sign cancelling
Transformation of probability density
the probability density function is defined as:
given , to transform to probability about , slice .
if is monotonically decrease in
if is monotonically increase in :
take derivative of , apply chain rule:
and both cases generate the same expression:
So for piecewise monotonic :
Proof of LOTUS
this leads to LOTUS:
the potential negative sign of also cancel with the potential flipping of integral limit caused by substituting variables in definite integral:
Solutions
scalar case
Proof of
definition of
applying LOTUS:
Thus:
Proof of
Definition of
\mathrm{var}(X) := \sigma^{2} :=\mathbb{E}\left\[ \left( X - \mu \right) ^{2} \right]applying LOTUS, the direct consequence of the definition of is:
so:
\begin{align} \mathrm{var}(x+b) &= \mathbb{E}\left\[(x+b)^{2}\right] - \left(\mathbb{E}\[x+b]\right)^{2} \\ &= \mathbb{E}\[x^{2} + 2bx + b^{2}] - \left( \mu^{2} + 2b\mu + b^{2} \right) \\ & = \mathbb{E}\[x^{2}] - \mu^{2} = \mathrm{var}(x) \end{align}thus:
Vector case
Let’s say , and
Proof of :
Definition of expectation on a vector/matrix of random variables:
in the case of vector or matrix, addition is element-wise, so it’s easy to know:
When it comes to vector-multiplication, assume is a vector, and is a random variable, then the -th element of vector is:
so .
When it comes to matrix-multiplication, applying linearity of expectation in scalar space:
thus:
The definition of is:
This match the outer product rule:
applying the rule :
applying the rule
with the results above, we have:
Problem 1.2 Properties of Independence
multivariate version of LOTUS (continuous case):
independency implies the joint probability density is the product of the marginal probability density:
By applying both LOTUS:
so for , it will be zero if and are independent:
Problem 1.3 Uncorrelated vs Independence
Relationship uncorrelated: \left{ (x,y) | \mathrm{cov}(x,y)=0 \right} uncorrelated independence, independence uncorrelated
and are uncorrelated:
\begin{align} \mu\_{x} &= \sum\_{x} \frac{1}{4} x = \frac{1}{4} (1 + 0 + -1 + 0) = 0 \\ \mu\_{y} & = \sum\_{y} \frac{1}{4} y = \frac{1}{4}(0 + 1 + 0 + -1) = 0 \\ \mathrm{cov}(x, y) &= \sum\_{x} \sum\_{y} \frac{1}{4} (x - \mu\_{x}) (y - \mu\_{y}) \\ &=\frac{1}{4} \sum\_{x} \sum\_{y} xy \\ &= \frac{1}{4} \left\[ (1\times 0) + (0 \times 1) + (-1 \times 1) + (0 \times -1) \right] \\ & = 0 \end{align}marginal distribution:
| p(x,y) | -1 | 0 | 1 | p(x) |
|---|---|---|---|---|
| -1 | 1/4 | 1/4 | ||
| 0 | 1/4 | 1/4 | 1/2 | |
| 1 | 1/4 | 1/4 | ||
| p(y) | 1/4 | 1/2 | 1/4 | 1 |
it’s apparently that , but , at , so and are not independent.
definition of the conditional expectation:
by law of total expectation:
is proven above, so and are uncorrelated.
Law of Total Expectation
Or called Iterated Expectation: take expectation on conditioned variables and then conditions generate the expectation on the joint distribution.
Problem 1.4 Sum of Random Variables
For any :
when and are independent, we have , so:
\begin{align} \mathrm{var}(x + y) &= \mathbb{E}\left\[ \left( x + y - \mu\_{xy} \right) ^2 \right] \\ &= \mathbb{E}\[x^2 + y^2 + 2xy -2\mu\_{xy}(x+y)+ \mu\_{xy}^{2}] \\ &= \mathbb{E}\[x^{2}] + \mathbb{E}\[y^{2}] + 2\mathbb{E}\[xy] - 2\mu\_{xy} (\mathbb{E}\[x] + \mathbb{E}\[y]) + \mu\_{xy}^{2} \\ &= \mathbb{E}\[x^{2}] + \mathbb{E}\[y^{2}] + 2\mathbb{E}\[x]\mathbb{E}\[y] - 2(\mathbb{E}\[x] + \mathbb{E}\[y] )^{2} + (\mathbb{E}\[x] + \mathbb{E}\[y])^{2} \\ &= \mathbb{E}\[x^{2}] + \mathbb{E}\[y^{2}] - \mathbb{E}\[x]^{2}-\mathbb{E}\[y]^{2} \\ &= \mathrm{var}(x) + \mathrm{var(y)} \\ \end{align}Problem 1.5 Expectation of an Indicator Variable
Problem 1.6 Multivariate Gaussian
Quadratic Form 二次型
Multivariate Gaussian: a probability density over real vectors (join probability)
With a diagonal convariance matrix:
The Mahalanobis distance would be:
The determinant of would be:
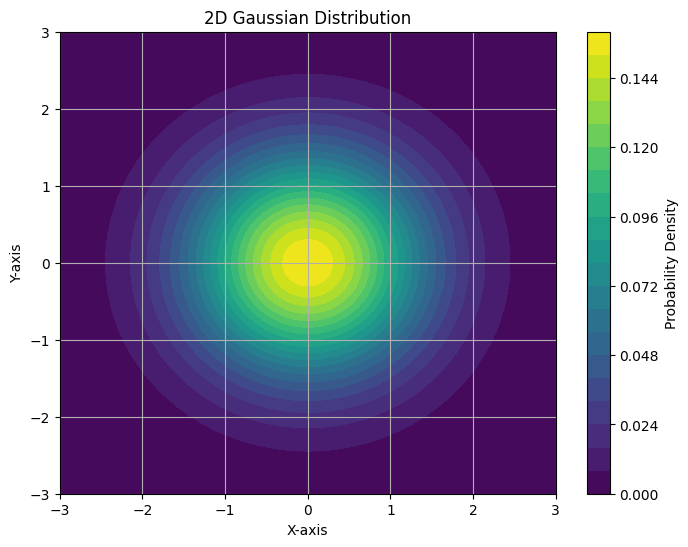
So the density becomes the product of univariate gaussian, indicating that a diagonal covariant matrix make sure the variables are independent:
with , the gaussian is squeezed in y dimension.
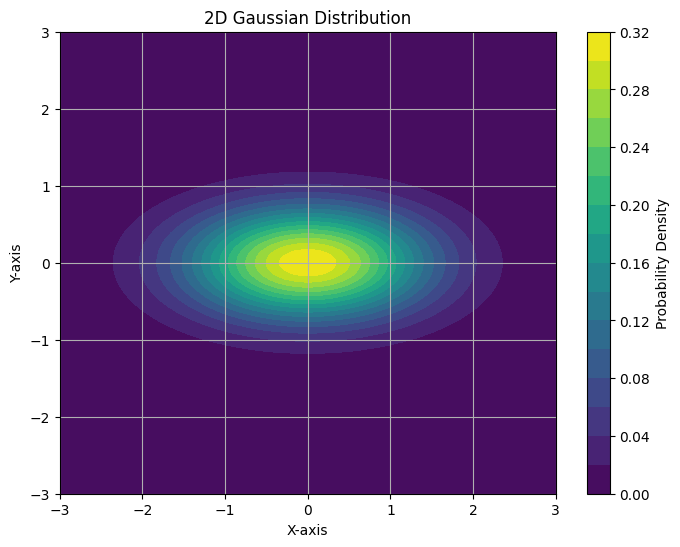
with , all components are i.i.d.
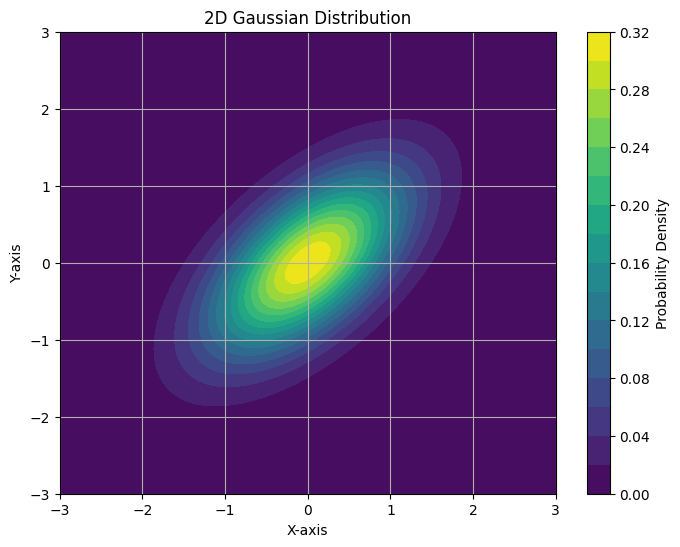
eigen-decompose
let Mahalanobis distance could be:
: centering : rotate and scale , so they are independent and normalized.
Eigenvalue and Eigenvector: , Since is a solution for , to get additional values, its determinant should be zero. Apply this idea to :
Eigenvector define the direction, and small eigenvalue center the distribution, while large eigenvalue sparse the distribution (more covariance).
Problem 1.7 Product of Gaussian Distributions
\begin{align} \mathcal{N} (x | \mu\_{1}, \sigma\_{1}^{2}) &\mathcal{N} (x | \mu\_{2}, \sigma\_{2}^{2})\\ \= & \frac{1}{\sqrt{2\pi} \sigma\_{1}^{2}} \frac{1}{\sqrt{ 2\pi } \sigma\_{2}^{2}}\exp\left( -\frac{1}{2} \left( \frac{(x-\mu\_{1})^{2}}{\sigma\_{1}^{2}} + \frac{(x-\mu\_{2})^{2}}{\sigma\_{2}^{2}} \right) \right) \\ \= & \frac{1}{\sqrt{2\pi} \sigma\_{1}^{2}} \frac{1}{\sqrt{ 2\pi } \sigma\_{2}^{2}}\exp\left( -\frac{1}{2} \frac{\left( (\sigma\_{1}^{2} + \sigma\_{2}^{2})x^{2}-2(\mu\_{1}\sigma\_{2}^{2} + \mu\_{2}\sigma\_{1}^{2})x + (\mu\_{1}^{2}\sigma\_{2}^{2}+\mu\_{2}^{2}\sigma\_{1}^{2})\right)}{\sigma\_{1}^{2}\sigma\_{2}^{2}} \right) \\ \end{align}
transform:
A Gaussian distribution can be identified:
Now process the rest of the expression
the remaining part of exponent part of is times:
\begin{align} &\frac{(\mu\_{1}^{2}\sigma\_{2}^{2}+\mu\_{2}^{2}\sigma\_{1}^{2})}{\sigma\_{1}^{2}\sigma\_{2}^{2}} - \frac{\left(\frac{\mu\_{1}\sigma\_{2}^{2}+\mu\_{2}\sigma\_{1}^{2}}{\sigma\_{1}^{2}+\sigma\_{2}^{2}}\right)^{2}}{\sigma\_{1}^{2}\sigma\_{2}^{2}} \\ \=& \frac{(\mu\_{1}^{2}\sigma\_{2}^{2}+\mu\_{2}^{2}\sigma\_{1}^{2})(\sigma\_{1}^{2}+\sigma\_{2}^{2})}{\sigma\_{1}^{2}\sigma\_{2}^{2}(\sigma\_{1}^{2}+\sigma\_{2}^{2})} - \frac{\mu\_{1}^{2}\sigma\_{2}^{4}+\mu\_{2}^{2}\sigma\_{1}^{4} + 2\mu\_{1}\mu\_{2}\sigma\_{1}^{2}\sigma\_{2}^{2}}{\sigma\_{1}^{2}\sigma\_{2}^{2}(\sigma\_{1}^{2}+\sigma\_{2}^{2})} \\ \=& \frac{\left(\mu\_{1}^{2}+\mu\_{2}^{2}\sigma\_{1}^{2}\sigma\_{2}^{-2}+\mu\_{1}^{2}\sigma\_{1}^{-2}\sigma\_{2}^{2} + \mu\_{2}^{2} \right) - \left(\mu\_{1}^{2}\sigma\_{1}^{-2}\sigma\_{2}^{2} + \mu\_{2}^{2}\sigma\_{1}^{2}\sigma\_{2}^{-2} + 2\mu\_{1}\mu\_{2} \right)}{\sigma\_{1}^{2}+\sigma\_{2}^{2}} \\ \=& \frac{(\mu\_{1} - \mu\_{2})^{2}}{\sigma\_{1}^{2}+\sigma\_{2}^{2}} \end{align}This could also be treated as an fixed value Gaussian:
And the Remaining factor is:
\begin{align} &\sqrt{ 2\pi(\sigma\_{1}^{2} + \sigma\_{2}^{2}) } \frac{1}{\sqrt{ 2\pi } \sigma\_{1}^{2}} \frac{1}{\sqrt{ 2\pi}\sigma\_{2}^{2}} \\ \=& \frac{\sigma\_{1}^{-2}+ \sigma\_{2}^{-2}}{\sqrt{ 2\pi }} \\ \=& \frac{1}{\sqrt{ 2\pi }\sigma\_{3}^{2}} \end{align}which match the form of Gaussian together with the exponential part. So the overall distribution expression is:
The resulting scaled Gaussian means this could not hold unless the scaling factor is 1
Problem 1.8 Product of Multivariate Gaussian Distributions
\begin{align} & \mathcal{N}(x | a, A) \mathcal{N}(x | b, B) \\ \=& \frac{1}{(2\pi)^{d/2}|A|^{1/2}}\exp\left( -\frac{1}{2}||x-a||_{A}^{2} \right) \frac{1}{(2\pi)^{d/2}|B|^{1/2}}\exp\left( -\frac{1}{2}||x-b||_{B}^{2} \right) \\ \=& \frac{1}{(2\pi)^{d}|A|^{1/2}|B|^{1/2}} \exp\left( -\frac{1}{2} \left( (x-a)^TA^{-1}(x-a) + (x-b)^T B^{-1} (x-b) \right) \right) \\ \end{align}expand the exponent term, and then complete the square:
\begin{align} \&x^T(A^{-1}+B^{-1})x-2x^T(A^{-1}a +B^{-1}b) + a^TA^{-1}a + b^TB^{-1}b \\ \=& (x - c)^T(A^{-1} + B^{-1}) (x - c) + e \\ \\ C=&(A^{-1}+B^{-1})^{-1} \\ c=& C(A^{-1}a + B^{-1}b) \\ e=& (a^T A^{-1} a + b^TB^{-1}b) - (A^{-1}a + B^{-1}b)^T(A^{-1}+B^{-1})^{-1}(A^{-1}a + B^{-1}b) \\ \=& \dots& \end{align}so the Gaussian part of the product is:
leaving the coefficient as:
to figure out , apply Woodbury matrix identity to simplify the nested inverse. Simply applying Woodbury Identity introduce two terms, so we make further transformation:
\begin{align} (A^{-1} + B^{-1})^{-1} &= A - A(B + A)^{-1}A \\ &= A(B+A)^{-1} \left\[ (B+A) - A \right] \\ & = A(A+B)^{-1}B \end{align}so the last term of e should be:
\begin{align} & (a^TA^{-1} + b^{T}B^{-1})(A(A+B)^{-1}B)(A^{-1}a + B^{-1}b) \\ \=& (a^{T} + b^{T}B^{-1}A)(A+B)^{-1} (BA^{-1}a + b) \\ \= & a^{T}(A+B)^{-1}BA^{-1}a + b^{T}B^{-1}A(A+B)^{-1}BA^{-1}a + a^{T}(A+B)^{-1}b + b^{T}B^{-1}A(A+B)^{-1}b \\ \end{align}Combining the two terms in would have:
\begin{align} & \left(a^{T}A^{-1}a - a^{T}(A+B)^{-1}BA^{-1}a \right) \\ \=& a^{T} \left( I - (A+B)^{-1}B \right) A^{-1}a \\ \=& a^{T}(A+B)^{-1}a \end{align}also:
\begin{align} & (b^{T}B^{-1}b - b^{T}B^{-1}A(A+B)^{-1}b) \\ \=& b^{T}B^{-1}(I - A(A+B)^{-1})b \\ \=& b^{T}(A+B)^{-1}b \end{align}observe the second term, we apply Exchange Identity here:
and since is symmetric, so
and the coefficient is:
\begin{align} & \frac{|A^{-1}+B^{-1}|^{1/2}}{(2\pi)^{d/2} |A|^{1/2}|B|^{1/2}} \\ \=& \frac{|A(A+B)^{-1}B|^{1/2}}{(2\pi)^{d/2} |A|^{1/2}|B|^{1/2}} \\ \=& \frac{1}{(2\pi)^{d/2}|A+B|^{1/2}} \end{align}This transformation procedure use a lot rules of Determinant
The coefficient and the redundant exponential term also form a fixed-value Gaussian:
So the product of multivariable Gaussian is:
Woodbury Matrix Identity
Inverting after low rank modification with low cost
Motivation: if you’ve inverted a large matrix , inverting it after added a low-rank update should not have to start from scratch
- : the core update,
- : bring the update into the space of ,
How to construct the invert
- subtract the correction: adding something to the original matrix usually “shrink” the inverse \begin{align} &(A+UCV)(A^{-1} - \mathrm{Correction})\\ \=& (I + UCVA^{-1}) - (A+UCV)(\mathrm{Correction}) \\ \=& I + UCVA^{-1} - UC(C^{-1}U^{-1}A + V)(\mathrm{Correction}) \end{align}
To cancel the last to terms, we can build correction with a sandwich structure to match the terms of :
- there is a in the back
- we don’t want to invert , even it’s invertible, so there should be a in the form
- let’s call the remaining part So the Correction term should have the form: so we have the last term as: The only unknown matrix here is , compare with , the only difference is the last term has a inside, making this so we are able to cancel these two terms:
So the correction term should be
the inverse should belike:
Notice that we assume is invertible, which does not always hold. But surprisingly this form also hold when is not invertible. It can be verified by the same process above.
Problem 1.9 Correlation between Gaussian Distributions
Warning
Do not mix the concept of Correlation and Covariance
correlation between distribution is defined as:
Using problem 1.8, The correlation between two Gaussian distributions is:
\begin{align} & \int \mathcal{N}(x|a,A)\mathcal{N}(x|b,B) dx \\ \=& \int \mathcal{N}(a|b, A + B) \mathcal{N} (x|c, C) dx \\ \=& \mathcal{N}(a|b, A+ B) \end{align}Problem 1.10 Completing the square
Problems 1.11 Eigenvalues
trace is defined as the sum of the diagonal
eigenvalues are roots of the characteristic function:
the latter equivalence is guarantee by Identity Theorem for Polynomials
let , then: