Linear Classifiers
Generative Classifier
- Learn CCDs from data:
- BDT to get decision rule
Data used in step 1, decision is secondary.
- Density estimation is an ill-posed problem (difficult)
- which density to use?
Vapnik's advice
when solving a given problem, try to avoid solving a more difficult problem as an intermediate step.
Solve for decision rule directly
Linear Classifier (binary)
- input:
- output:
- find a linear function:
- separate input space into 2 halp-spaces
- points to into the pos-space
- is the dec boundary
Decision Rule
bias term can be included in
f(\tilde{x}) = \tilde{w}\tilde{x}= \begin{bmatrix} w \\ b \\ \end{bmatrix} \begin{bmatrix} x \\ 1 \end{bmatrix} \= w^{T}x+b
Training Set
Given a :
- correctly classified
- misclassified
Idea case: 0-1 loss failed because has only 0 or undefined gradient.
Least Squares Classification (Label Regression)
FLD is a version of LSC
Perceptron
Rosenblatt 1962
criteria: only look at misclassified points
M = set of misclassified points =
loss function, larger loss for for misclassified points far from boundary:
Perceptron Algorithm:
look at one sample at a time and minimize (gradient descent)
it’s now called stochastic gradient descent, SGD
How to set the learning rate
- rotate towards the misclassified point
- length of increases in each iteration, each update has less effect than prev

Rosenblatt proved SGD converges in iterations if the data is linearly separate
: for , : the optimal unit weight vector that perfectly separates the two classes with the maximum possible margin.
- many possible solution, based on initialization
- does not converge if data is not linearly separable.
Logistic Regression
(probabilistic Approach)
Binary class:
PS6-7: when the CCD are Gaussian, , the posterior is is a sigmoid function
where f(x) is linear
Sigmoid:
with BDR, was determined by CCD. Now we directly learn
linear func: prob:
Decision Rule:
Look at # parameters
- BDR-Gauss:
- Logistic Regression: , less likely to overfit.
Learning: parameter estimation
let Bernoulli likelihood: Data log-likelihood:
MLE:
Find zero-crossings of gradient: Newton-Raphson Method
weighted lesat squares: weights are , target is
R: weights depend on , weight higher on unconfident predictions z: - error between pred and target depends on
IRLS, IRWLS: iterative reweighted least squares
Comparison of Error (loss) functions
all have the form:
“empirical risk minimization” - reduce the training error.
let
Ideal 0-1 loss
LSC:
penalizing too correct answers
Perceptron:
some loss for correctly classified points: the effect is to push. the boundary away from the nearby points.
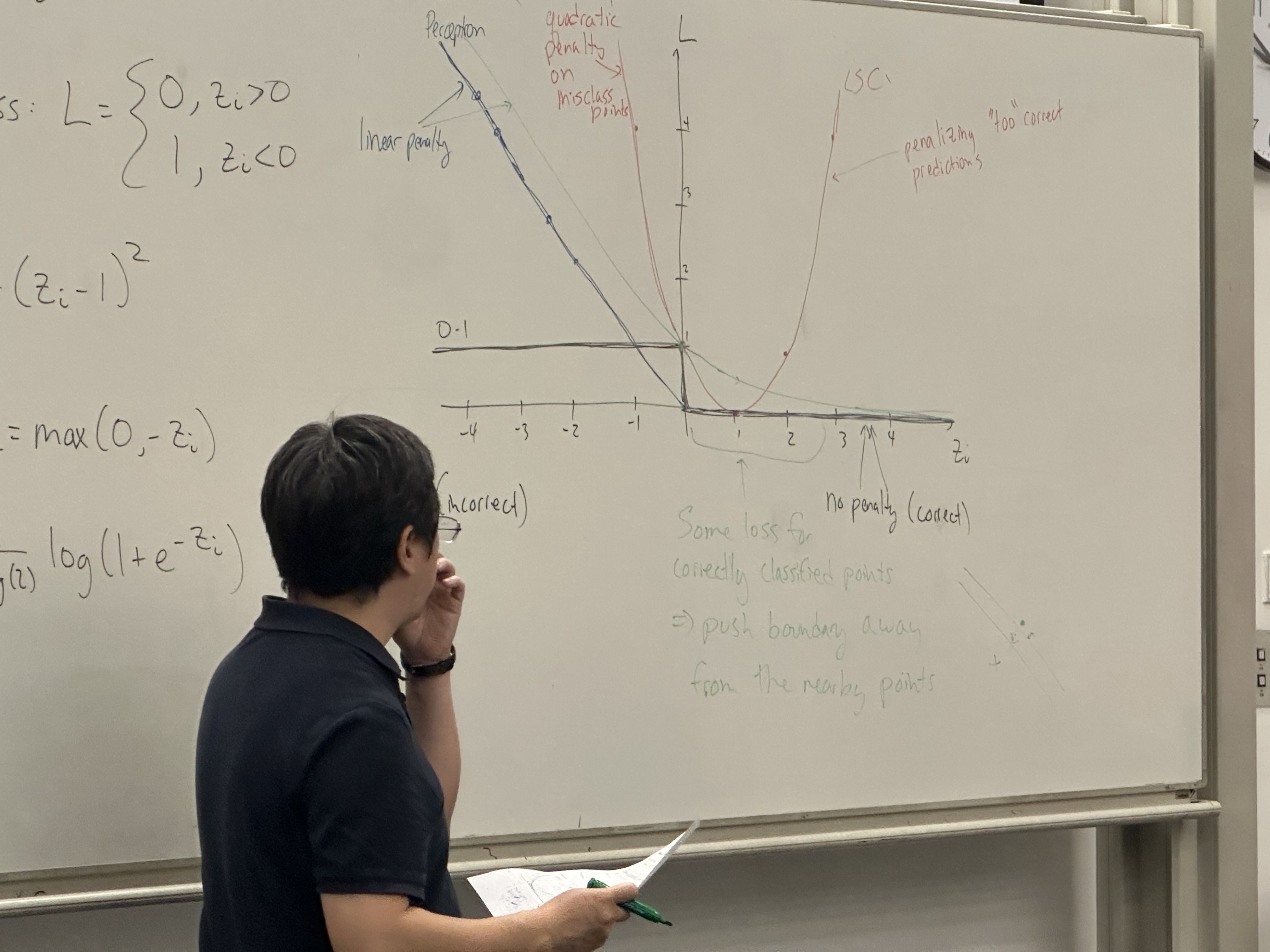
Loss for LSC & LR are convex approx to 0-1 loss